论文引用数:预知未来
本文充斥臆测内容,并非科学研究,请在教授陪同下阅读。
研究背景
最近要申请一个奖,少不了要看自己的发表论文情况。我已经把自己的论文整理到谷歌学术了,直接去那里看就可以。
呀!我的引用数已经超过一百了!前几天我看的时候它还停留在90多就停滞不前了,没想到这么快就突破了100,立即进入无限自我陶醉的状态。
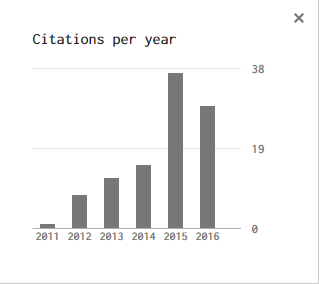
盯着自己的数据,突然发现这数据还是挺有规律的,立马想到一个问题:能否预测未来的引用数呢?

研究方法
这里我用一段JavaScript代码获取每年的引用数[1]:
1 | var get_years = document.querySelectorAll("span.gsc_g_t"); |
用法是在形如https://scholar.google.com/citations?hl=en&user=换成你的&view_op=citations_histogram的页面执行这段代码,数据复制粘贴到Octave里分析。
我还找来Lorenzo Stella的引用数进行分析。虽然他做的工作和我不一样,但我看过他的很多篇文献,觉得以他为样本进行分析是合理的。
统计分析
我觉得我的引用情况可以用$y = ax^2 + bx +c$来描述。对于这种多项式Octave可以很简单的用polyfit进行拟合:
1 | # 手动删掉最后一年的。 |
就是说,在$y$年时我的引用数$C = 2.0714 y^2 - 8.3317 \times 10^3 y + 8.3779 \times 10^6$。Octave里可以直接根据这一公式来求后面的值,也就是预测之后的引用数。根据这一公式,2016年和2017年我的引用数分别为:
1 | prediction = polyval(my, [2016 2017]); |
就是说今年和明年我的引用数应该是53和75。让我们看看理论预测的结果是否可靠罢。
2017-1-6 Update: 2016年的被引数是54,超过了预期,和预测相符的非常好。
等等,其实我们完全可以用其他研究者的例子来研究。这里我把上面的过程写成了一个函数:
1 | # 删掉了两年的数据。 |
就是说2015和2016年的引用数是360和401,仅从2015年的数据看还是挺准的(他2015年实际的数值是353!)。
结论
- 可以预测。
- 预测性有赖研究者的「发育」情况。
- 期待对更多人进行测试。
- 我想把这东西做成个网页供其他人使用。
原来NodeList和Array不一样,不能用for...in和forEach而应该用for...of ↩
或者您可以把评论发在别处,添加指向本页的连接,然后把网址告诉我:
本文标题:论文引用数:预知未来
文章作者:Chris
发布时间:2016-06-21
最后更新:2025-03-16
原始链接:https://chriszheng.science/2016/06/21/Citations-cast-ourselves-into-the-future/
版权声明:本博客所有文章除特别声明外,均采用 CC BY 4.0 许可协议。转载请注明出处!
分享